GitOps – Kubernetes auf die einfache Art: Teil 1
Teil I: Bewährte Praktiken mit Kubernetes-Verwaltungstechniken
Die Verwaltung von Kubernetes sollte einfach, unkompliziert und klar sein. Bekannte DevOps-Praktiken und letztendlich Automatisierung sollten durch die Managementtechnik zugänglich sein. Das erste GitOps-Prinzip, der deklarative Ansatz, ist die wesentliche Kubernetes-Verwaltungstechnik, um den gewünschten Funktionsumfang zu nutzen.
Einführung
Dies ist der erste Artikel einer Reihe über GitOps und seine Paradigmen, um das Konfigurationsmanagement von Kubernetes zu vereinfachen. Die vier GitOps-Prinzipien sind: deklarativer Ansatz:
- Das gesamte System wird deklarativ beschrieben,
- Versionskontrolle: Der kanonisch gewünschte Systemzustand wird in Git versioniert,
- Bereitstellungsautomatisierung: Genehmigte Änderungen werden automatisch auf das System angewendet.
- Kontinuierliche Lieferung: Software-Agenten sorgen für Korrektheit und Alarmierung bei Abweichungen.
In diesem Artikel werden verschiedene Kubernetes-Verwaltungstechniken vorgestellt und die Bedeutung und der Wert des deklarativen Ansatzes hervorgehoben. Der deklarative Ansatz ist das erste GitOps-Prinzip und empfiehlt, das gesamte System deklarativ zu beschreiben. In den folgenden Abschnitten werden drei Kubernetes-Verwaltungstechniken erläutert. Eine Technik ist ein Ansatz ohne Kubernetes-Objektkonfigurationsdateien:
- zwingende Befehle.
Die anderen beiden Techniken basieren auf Kubernetes-Objektkonfigurationsdateien:
- zwingende Objektkonfiguration,
- deklarative Objektkonfiguration.
Imperative Befehle
Objekte erstellen
Die einfachste Art der Interaktion mit der Kubernetes-API sind zwingende Befehle. Diese Verwaltungstechnik funktioniert ohne Kubernetes-Objektkonfigurationsdateien, aber mit zwingenden Schritten. Imperative Befehle können in verbgesteuerte und objektgesteuerte Befehle eingeteilt werden. Beispielsweise kann ein Deployment-Objekt für die Abstimmungscontainer durch einen verbgesteuerten, imperativen Befehl generiert werden:
kubectl run vote --image=andywirtzk8s/voting-vote:v1.0 --port=8080 -l "app=vote" -r 3 -n voting
Mit diesem Befehl wird das Vote-Deployment-Objekt im Voting-Namespace von Kubernetes erstellt. Die Objekterstellung erfordert nur einen einzigen Schritt und es ist keine Konfigurationsdatei erforderlich. Das Bild finden Sie bei Dockerhub. Ein Serviceobjekt für die Abstimmungscontainer kann generiert werden mit:
kubectl expose deployment vote --name vote -n voting
Mit diesem Befehl wird das Vote-Service-Objekt im Voting-Namespace von Kubernetes erstellt. Ein HorizontalPodAutoscaler-Objekt für die Abstimmungscontainer kann generiert werden mit:
kubectl autoscale deployment vote --min 2 --max 5 --cpu-percent 80 --name vote -n voting
Mit diesem Befehl wird das Vote HorizontalPodAutoscaler-Objekt im Voting-Namespace von Kubernetes erstellt. Diese drei Befehle sind verbgesteuert. Der nächste Befehl ist objektgesteuert. Mit dem objektgesteuerten Befehl können verschiedene Kubernetes-Objekte erstellt werden. Ein ConfigMap-Objekt für die Abstimmungscontainer kann beispielsweise generiert werden mit:
kubectl create configmap options --from-literal A=Imperative --from-literal B=Declarative -n voting
Mit diesem Befehl wird das Options-ConfigMap-Objekt im Voting-Namespace von Kubernetes erstellt. Abbildung 1 zeigt die vier zwingenden Befehle zum Erstellen von Kubernetes-Objekten.

Figure 1: Create objects with imperative commands.
Objekte aktualisieren
Die Verwaltungstechnik mit zwingenden Befehlen zur Interaktion mit der Kubernetes-API kann auch zum Ändern von Kubernetes-Objekten verwendet werden. Drei verfügbare Imperativbefehle sind verbgesteuert. Beispielsweise kann ein Deployment-Objekt horizontal skaliert werden mit:
kubectl scale deployment vote --replicas 2 -n voting
Mit diesem Befehl wird das Replikatfeld des Vote-Bereitstellungsobjekts im Voting-Namespace von Kubernetes aktualisiert. Die Änderung erfordert nur einen einzigen Schritt und es ist keine Konfigurationsdatei erforderlich. Ein Kubernetes-Objekt kann mit folgenden Anmerkungen versehen werden:
kubectl annotate deployment vote atix.de/technique='imperative commands' -n voting
Mit diesem Befehl wird das Anmerkungsfeld des Vote-Deployment-Objekts im Voting-Namespace von Kubernetes aktualisiert. Ein Kubernetes-Objekt kann wie folgt gekennzeichnet werden:
kubectl label deployment vote technique=imperative -n voting
Mit diesem Befehl wird das Labels-Feld des Vote-Deployment-Objekts im Voting-Namespace von Kubernetes aktualisiert. Alternativ kann ein aspektgesteuerter Befehl verwendet werden. Mit einem aspektgesteuerten Befehl können verschiedene Felder für verschiedene Kubernetes-Objekte geändert werden. Das Feld eines Kubernetes-Objekts kann beispielsweise wie folgt geändert werden:
kubectl set image deployment vote vote=andywirtzk8s/voting-vote:v1.1 -n voting
Mit diesem Befehl wird das Bildfeld der Pod-Vorlage des Vote-Deployment-Objekts im Voting-Namespace von Kubernetes aktualisiert und ein rollierendes Update ausgelöst. Darüber hinaus gibt es zwei zwingende Befehle mit einem allgemeineren Ansatz zum Ändern von Live-Kubernetes-Objekten. Beispielsweise kann ein bestimmtes Feld eines Kubernetes-Objekts durch eine Patch-Zeichenfolge geändert werden mit:
kubectl patch deployment vote -p '{"spec": {"minReadySeconds": 10}}' -n voting
Mit diesem Befehl wird das minReadySeconds-Feld des Vote-Deployment-Objekts im vote-Namespace von Kubernetes aktualisiert. Hier ist ein Verständnis des JSON-Formats der Kubernetes-API-Ressourcen erforderlich. Für größere Änderungen an einem Kubernetes-Objekt kann das Live-Objekt im Standardeditor geöffnet werden mit:
kubectl edit deployment vote -n voting
Mit dem Editor können Änderungen vorgenommen und gespeichert werden. Zum Beispiel:
...
- image: andywirtzk8s/voting-vote:v1.1
name: vote
envFrom:
- prefix: OPTION_
configMapRef:
name: options
livenessProbe:
httpGet:
path: /
port: http
readinessProbe:
httpGet:
path: /
port: http
ports:
- containerPort: 8080
name: http
...
In diesem Beispiel werden die Felder envFrom, livenessProbe, readinessProbe und ports[0].name zum Live-Deployment-Objekt hinzugefügt. Nachdem Sie diese Änderungen vorgenommen, die Datei gespeichert und den Editor beendet haben, wird das Vote-Bereitstellungsobjekt im Voting-Namespace von Kubernetes aktualisiert und ein fortlaufendes Update ausgelöst. Hier ist ein Verständnis des YAML-Formats der Kubernetes-API-Ressourcen erforderlich. Abbildung 2 zeigt die sechs zwingenden Befehle zum Aktualisieren von Kubernetes-Objekten.
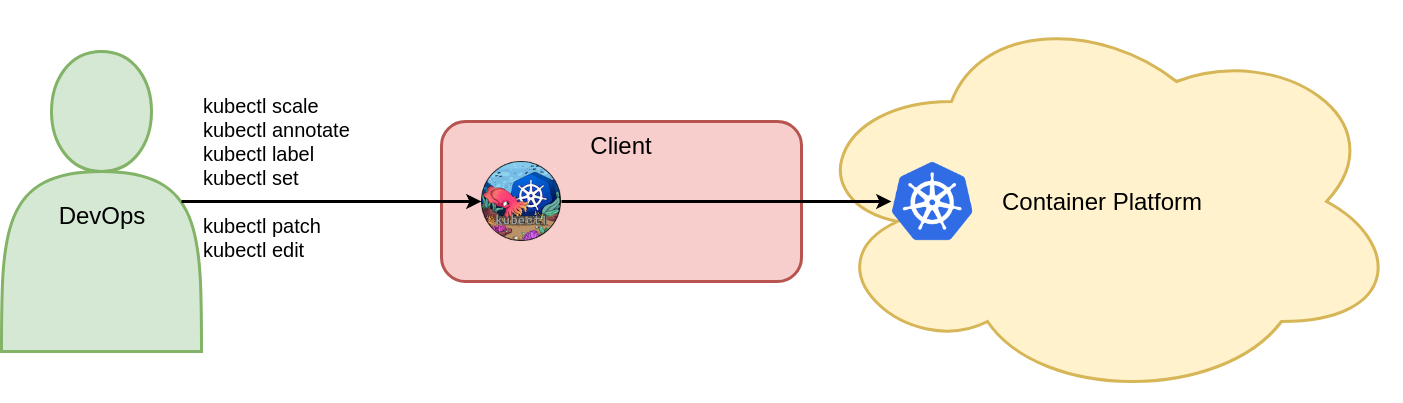
Figure 2: Update objects with imperative commands.
Objekte löschen
Um ein Kubernetes-Objekt zu löschen, gibt es einen zwingenden objektgesteuerten Befehl. Ein Kubernetes-Objekt kann beispielsweise wie folgt gelöscht werden:
kubectl delete deployment vote -n voting
Mit diesem Befehl wird das Vote-Deployment-Objekt im Voting-Namespace von Kubernetes gelöscht. Abbildung 3 zeigt den einen zwingenden Befehl zum Löschen von Kubernetes-Objekten.
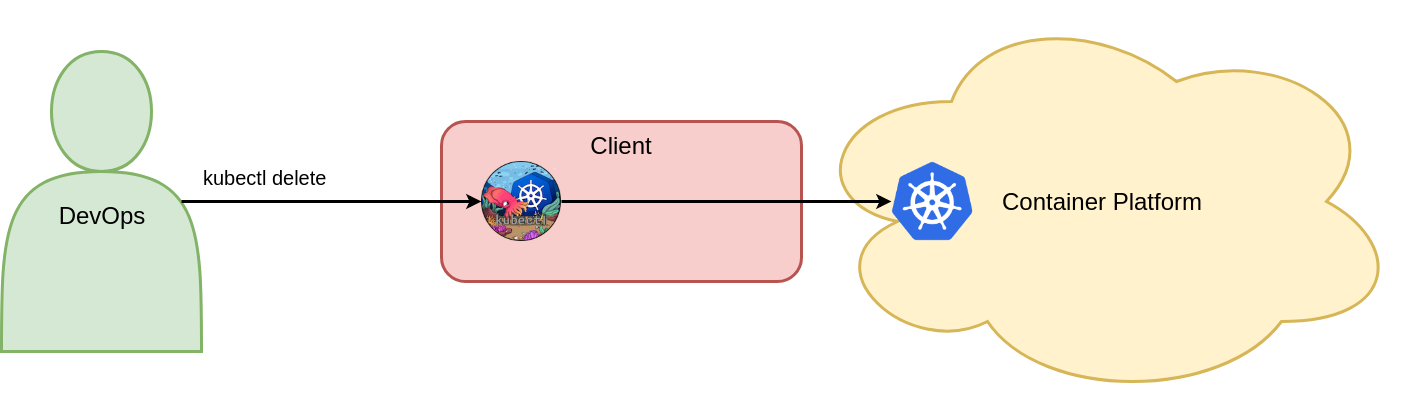
Figure 3: Delete objects with imperative commands.
Vorteile und Herausforderungen
Der große Vorteil der Kubernetes-Verwaltung mit imperativen Befehlen ist die Einfachheit. Imperative Befehle sind einfach, leicht zu erlernen und leicht zu merken. Konfigurationsänderungen erfordern nur einen einzigen Schritt. Darüber hinaus können Änderungen an Kubernetes-Objekten von mehreren Autoren ohne Konflikte vorgenommen werden. Der größte Nachteil der Kubernetes-Verwaltung mit imperativen Befehlen ist das Fehlen von Kubernetes-Objektkonfigurationsdateien. Ohne die Kubernetes-Objektkonfigurationsdateien ist eine Automatisierung, Standardisierung und Reproduzierbarkeit nicht möglich. Auf DevOps-Praktiken wie Quellcodeverwaltung, Änderungsüberprüfungsprozesse und Prüfprotokolle im Zusammenhang mit Änderungen kann nicht zugegriffen werden. Tabelle 1 listet die Funktionen der zwingenden Befehle zum Verwalten von Kubernetes-Objekten auf. Weitere Informationen zu dieser Managementtechnik finden Sie unter Imperative Befehle.
| Management technique | Imperative commands |
|---|---|
| Simplicity | ✅ |
| Multiple editors | ✅ |
| Operate on directories | ❌ |
| Source control | ❌ |
| Change review processes | ❌ |
| Audit trails | ❌ |
| Standardization | ❌ |
| Reproducibility | ❌ |
| Idempotence | ❌ |
| Automation | ❌ |
Table 1: Features of the imperative commands.
Imperative Objektkonfiguration
Objekte erstellen
Eine ausgefeiltere Art der Interaktion mit der Kubernetes-API ist die zwingende Objektkonfiguration. Diese Verwaltungstechnik funktioniert mit Kubernetes-Objektkonfigurationsdateien. Beispielsweise kann ein Deployment-Objekt für die Abstimmungscontainer in einer Datei definiert werden:
FILE=${HOME}/configs/voting/vote/deployment.yaml
Der Inhalt der Datei ist ein YAML-Deskriptor des Deployment-Objekts:
apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
atix.de/technique: imperative object configuration
labels:
app: vote
technique: imperative
name: vote
namespace: voting
spec:
minReadySeconds: 10
replicas: 3
selector:
matchLabels:
app: vote
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
type: RollingUpdate
template:
metadata:
labels:
app: vote
spec:
containers:
- image: andywirtzk8s/voting-vote:v1.0
name: vote
envFrom:
- prefix: OPTION_
configMapRef:
name: options
livenessProbe:
httpGet:
path: /
port: http
readinessProbe:
httpGet:
path: /
port: http
ports:
- containerPort: 8080
name: http
Dies ist ein YAML-Manifest, das den gewünschten Status des Deployment-Objekts darstellt. Dieses Deployment-Objekt kann generiert werden mit:
kubectl create -f ${FILE}
Mit diesem Befehl wird das Vote-Deployment-Objekt im Voting-Namespace von Kubernetes erstellt. Damit der Befehl funktioniert, ist es erforderlich, dass das Vote-Bereitstellungsobjekt im Voting-Namespace zuvor nicht vorhanden ist. Abbildung 4 zeigt den einen zwingenden Objektkonfigurationsbefehl zum Erstellen von Kubernetes-Objekten.
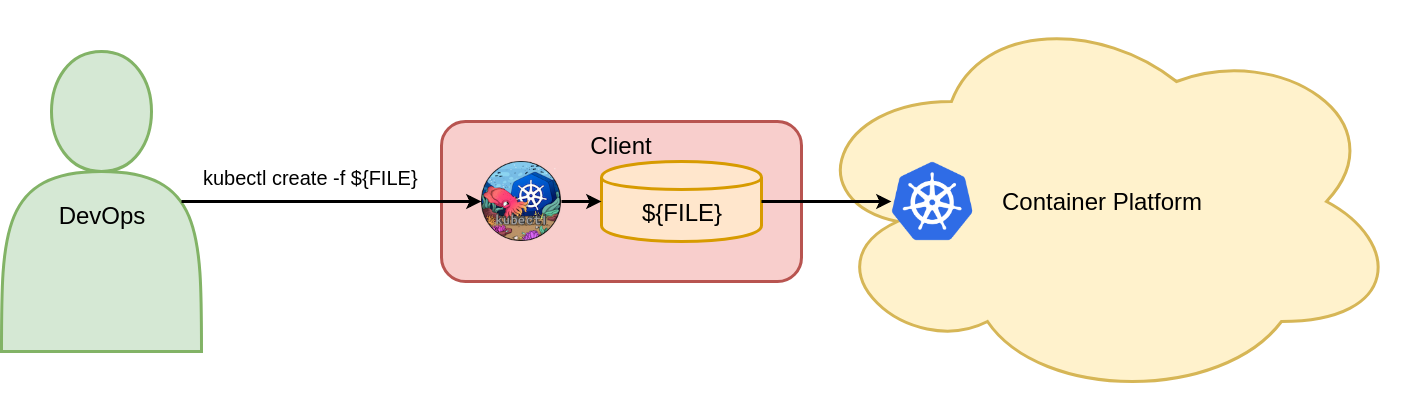
Figure 4: Create objects with imperative object configuration.
Objekte aktualisieren
Die Verwaltungstechnik der zwingenden Objektkonfiguration für die Interaktion mit der Kubernetes-API kann auch zum Ändern von Kubernetes-Objekten verwendet werden. Beispielsweise kann die Konfiguration des Bereitstellungsobjekts ersetzt werden durch:
kubectl replace -f ${FILE}
Abhängig von der im YAML-Manifest des Vote-Bereitstellungsobjekts vorgenommenen Änderung sorgt Kubernetes dafür, dass der neue gewünschte Status sichergestellt wird. Wenn das Replikatfeld geändert wird, wird das Live-Bereitstellungsobjekt horizontal skaliert. Wenn das Bildfeld in der Pod-Vorlage des Deployment-Objekts geändert wird, wird ein rollierendes Update ausgelöst. Kubernetes ersetzt das Live-Objekt, auch wenn keine Konfigurationsänderung erfolgt. Dies führt zu einem zwingenden, nicht idempotenten Konfigurationsmanagement. Damit der Befehl funktioniert, ist es erforderlich, dass zuvor das Vote-Bereitstellungsobjekt im Voting-Namespace vorhanden ist. Abbildung 5 zeigt den einen zwingenden Objektkonfigurationsbefehl zum Aktualisieren von Kubernetes-Objekten.
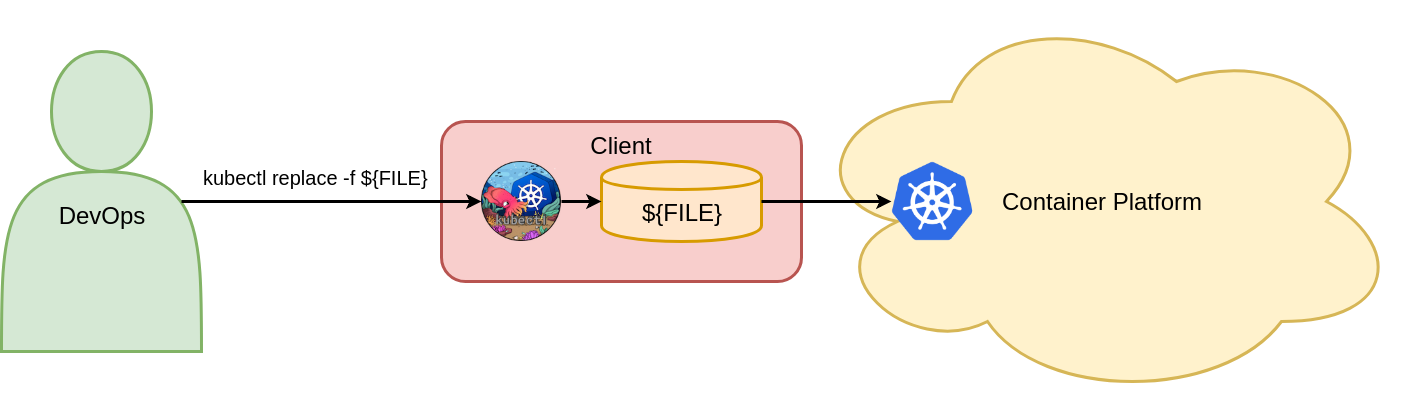
Figure 5: Update objects with imperative object configuration.
Objekte löschen
Um ein Kubernetes-Objekt zu löschen, gibt es einen Befehl innerhalb der zwingenden Objektkonfigurationstechnik. Ein Kubernetes-Objekt kann beispielsweise wie folgt gelöscht werden:
kubectl delete -f ${FILE}
Mit diesem Befehl wird das Vote-Deployment-Objekt im Voting-Namespace von Kubernetes gelöscht. Abbildung 6 zeigt den einen zwingenden Objektkonfigurationsbefehl zum Löschen von Kubernetes-Objekten.
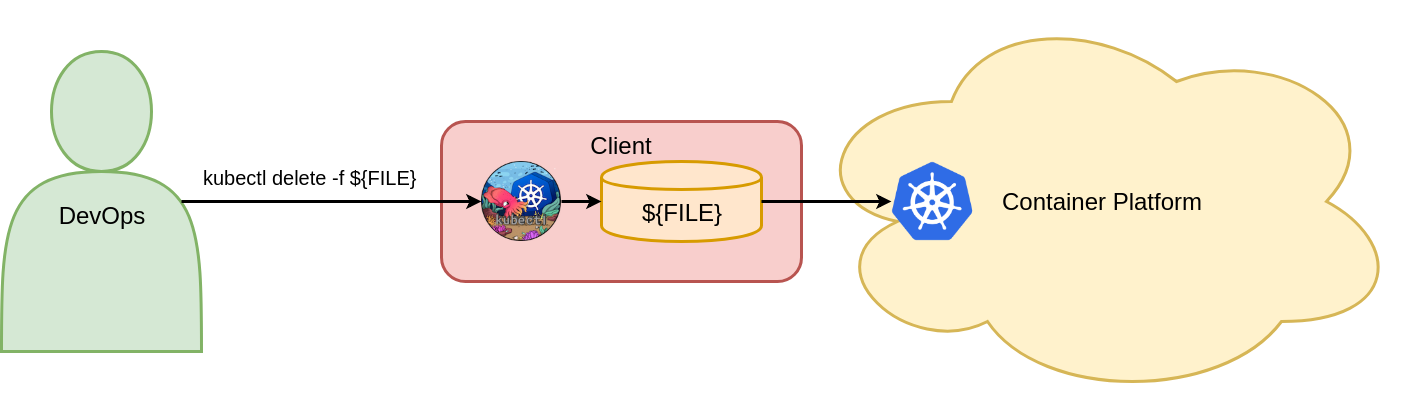
Figure 6: Delete objects with imperative object configuration.
Vorteile und Herausforderungen
Der große Vorteil des Kubernetes-Managements mit zwingender Objektkonfiguration ist die Aufzeichnung des gewünschten Zustands in Form von Kubernetes-Objektkonfigurationsdateien. Mit diesen Kubernetes-Objektkonfigurationsdateien können Standardisierung und Reproduzierbarkeit ermöglicht werden.
Auf DevOps-Praktiken wie die Verwendung eines Quellcodeverwaltungssystems, von Änderungsüberprüfungsprozessen und von mit Änderungen verbundenen Prüfpfaden kann zugegriffen werden. Der größte Nachteil des Kubernetes-Managements mit imperativer Objektkonfiguration ist das fehlende Feature des idempotenten Konfigurationsmanagements. Aktualisierungen erfolgen durch Ersetzen des Live-Objekts, auch wenn keine Konfigurationsabweichung zwischen der Konfigurationsdatei und dem Live-Objekt vorliegt.
Wenn mehrere Editoren dasselbe Kubernetes-Objekt verwalten, können Änderungen einer Quelle durch den Ersetzungsbefehl der zweiten Quelle verloren gehen. Solche Aktualisierungen von Live-Objekten müssen in den Konfigurationsdateien widergespiegelt werden. Darüber hinaus gibt es zusätzliche Anforderungen, damit die Befehle zum Erstellen und Ersetzen funktionieren. Die zwingende Objektkonfiguration funktioniert am besten für Dateien, nicht für Verzeichnisse. All diese Probleme erschweren die Durchführung oder Automatisierung von Konfigurationsänderungen. Tabelle 2 listet die Funktionen der zwingenden Objektkonfiguration für die Verwaltung von Kubernetes-Objekten auf. Weitere Informationen zu dieser Verwaltungstechnik finden Sie unter Imperative Objektkonfiguration.
| Management technique | Imperative object configuration |
|---|---|
| Simplicity | 🔶 |
| Multiple editors | ❌ |
| Operate on directories | 🔶 |
| Source control | ✅ |
| Change review processes | ✅ |
| Audit trails | ✅ |
| Standardization | ✅ |
| Reproducibility | ✅ |
| Idempotence | ❌ |
| Automation | ❌ |
Table 2: Features of the imperative object configuration.
Deklarative Objektkonfiguration
Objekte erstellen
Die ausgefeilteste Art der Interaktion mit der Kubernetes-API ist die deklarative Objektkonfiguration. Diese Verwaltungstechnik funktioniert mit Kubernetes-Objektkonfigurationsdateien. Es unterstützt den Betrieb von Verzeichnissen mit Kubernetes-Objektkonfigurationsdateien. Beispielsweise kann ein Verzeichnis definiert werden, das YAML-Deskriptordateien von Kubernetes-Objekten enthält:
DIR=${HOME}/configs/voting/vote
In diesem Verzeichnis werden die YAML-Manifeste gespeichert, die den gewünschten Status des Deployments, des Ingress und des Service-Objekts für die Abstimmungscontainer darstellen:
.
├── deployment.yaml
├── ingress.yaml
└── service.yaml
Die Dateien finden Sie auf Github. Die drei Kubernetes-Objekte können gedruckt werden mit:
kubectl diff -f ${DIR}/
Mit diesem Befehl werden die Objekte „vote Deployment“, „vote Ingress“ und „vote Service“ von Kubernetes gedruckt und können überprüft werden. Die Ausgabe zeigt nicht nur die in den YAML-Manifesten definierten Felder, sondern wird auch durch die Standardfeldwerte von Kubernetes angereichert. Die drei Kubernetes-Objekte können generiert werden mit:
kubectl apply -f ${DIR}/
Mit diesem Befehl werden die Objekte „vote Deployment“, „vote Ingress“ und „vote Service“ in Kubernetes gepostet und von Kubernetes im Voting-Namespace erstellt. Es gibt keine Anforderungen, ob die Objekte vorher existieren oder nicht. Abbildung 7 zeigt die beiden relevanten deklarativen Objektkonfigurationsbefehle zum Erstellen von Kubernetes-Objekten.
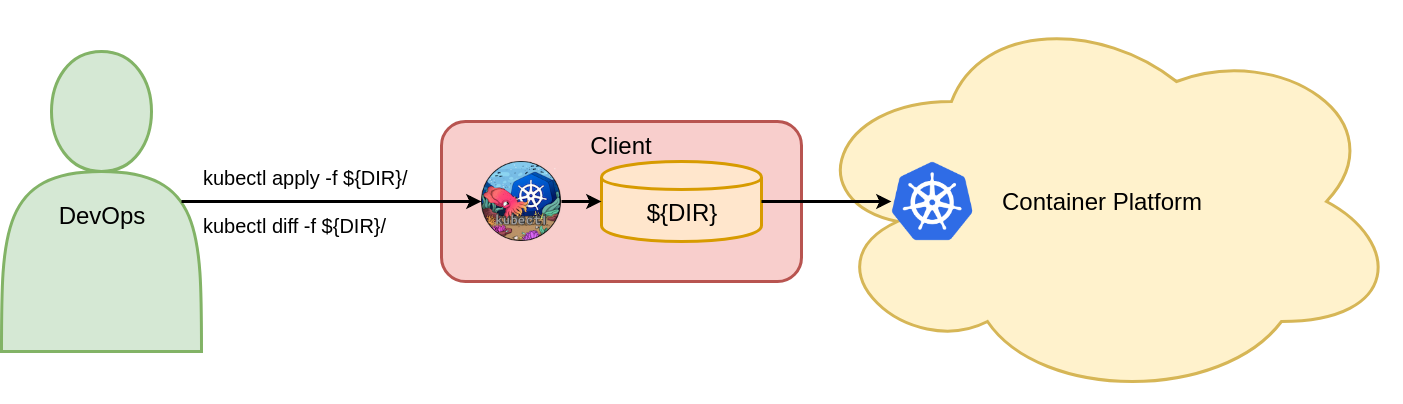
Figure 7: Create objects with declarative object configuration.
Objekte aktualisieren
Die Verwaltungstechnik der deklarativen Objektkonfiguration für die Interaktion mit der Kubernetes-API kann auch zum Ändern von Kubernetes-Objekten verwendet werden. Der Unterschied zwischen den lokal gespeicherten YAML-Manifesten und den Live-Kubernetes-Objektgegenstücken kann wie folgt ausgedruckt werden:
kubectl diff -f ${DIR}/
Mit diesem Befehl wird die Konfigurationsdrift des vote Deployment, des vote Ingress und der vote Service-Objekte von Kubernetes gedruckt und kann überprüft werden. Die Ausgabe zeigt nur die Felder, die nicht zwischen den lokal gespeicherten Kubernetes-Objektkonfigurationsdateien und den Live-Kubernetes-Objekten synchronisiert sind. Unabhängig davon, ob ein Unterschied angezeigt wird oder nicht, können die drei Kubernetes-Objekte aktualisiert werden mit:
kubectl apply -f ${DIR}/
Bei diesem Befehl müssen drei verschiedene Szenarien berücksichtigt werden. Im ersten Fall existierte das Kubernetes-Objekt vorher nicht. Hier wird es von Kubernetes erstellt, wie im letzten Unterabschnitt beschrieben. Im zweiten Fall gibt es keinen Unterschied zwischen dem YAML-Manifest und den Live-Kubernetes-Objekten. Hier wird keine Aktion ausgeführt. Im dritten Fall wurden ein oder mehrere Felder in einem oder mehreren Kubernetes-Objekten geändert.
Hier wird ein Merge-Patch berechnet und die Kubernetes-Objekte werden von Kubernetes gepatcht. Mit dieser Merge-Patch-Berechnung wird der gewünschte Systemzustand nicht nur deklarativ in den YAML-Manifesten beschrieben, sondern auch deklarativ an Kubernetes kommuniziert. Dies führt zu einem idempotenten Konfigurationsmanagement. Wenn beispielsweise das Replikatfeld und das Bildfeld in den lokal gespeicherten Kubernetes-Objektkonfigurationsdateien geändert werden, wird das Live-Bereitstellungsobjekt horizontal skaliert und eine fortlaufende Aktualisierung ausgelöst, während die Live-Ingress- und Service-Objekte unberührt bleiben. Wenn andererseits ein Feld nicht in der YAML-Manifestdatei definiert ist, wird es vom Befehl ignoriert.
Wenn einige zwingende Änderungen an Standardfeldwerten vorgenommen wurden, die nicht in einer Kubernetes-Objektkonfigurationsdatei definiert sind, wird diese Änderung nicht überschrieben. Abbildung 8 zeigt die beiden relevanten deklarativen Objektkonfigurationsbefehle zum Aktualisieren von Kubernetes-Objekten.
Figure 8: Update objects with declarative object configuration.
Objekte löschen
Zum Löschen von Kubernetes-Objekten gibt es einen Befehl innerhalb der deklarativen Objektkonfigurationstechnik. Die drei Kubernetes-Objekte können beispielsweise gelöscht werden mit:
kubectl delete -f ${DIR}/
Mit diesem Befehl werden das Vote-Deployment, der Vote-Ingress und die Vote-Service-Objekte im Voting-Namespace von Kubernetes gelöscht. Abbildung 9 zeigt den einen deklarativen Objektkonfigurationsbefehl zum Löschen von Kubernetes-Objekten.
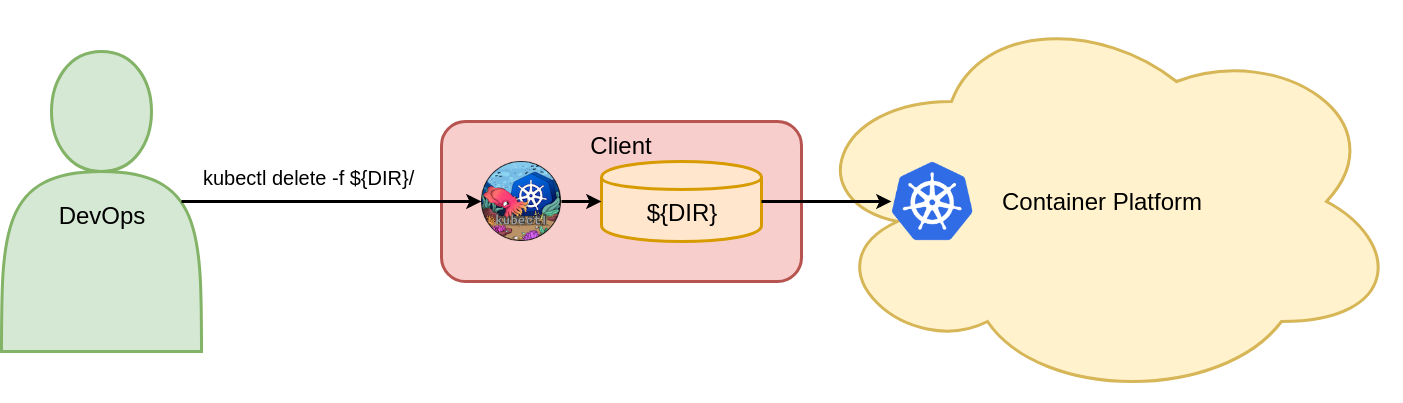
Figure 9: Delete objects with declarative object configuration.
Vorteile und Herausforderungen
Der Hauptvorteil der Kubernetes-Verwaltung mit deklarativer Objektkonfiguration ist die Unterstützung für den Betrieb in Verzeichnissen, die Kubernetes-Objektkonfigurationsdateien enthalten, und die automatische Erkennung des Operationstyps pro Objekt. Kubernetes kann automatisch entscheiden, ob ein Objekt oder Feld erstellt, gepatcht, gelöscht oder unangetastet bleiben soll. Dies ermöglicht ein idempotentes Konfigurationsmanagement.
Mit den Verzeichnissen, die die Kubernetes-Objektkonfigurationsdateien enthalten, können Automatisierung, Standardisierung und Reproduzierbarkeit ermöglicht werden. Auf DevOps-Praktiken wie die Verwendung eines Quellcodeverwaltungssystems, von Änderungsüberprüfungsprozessen und von mit Änderungen verbundenen Prüfpfaden kann zugegriffen werden.
Die Kubernetes-Verwaltung mit deklarativer Objektkonfiguration ist die leistungsstärkste Verwaltungstechnik. Dies ist mit den Kosten einer steileren Lernkurve verbunden, da die Berechnung der Patch-Zusammenführung zu unerwartetem Verhalten führen kann. Tabelle 3 listet die Funktionen der deklarativen Objektkonfiguration zur Verwaltung von Kubernetes-Objekten auf. Weitere Informationen zu dieser Verwaltungstechnik finden Sie unter deklarative Objektkonfiguration.
| Management technique | Declarative object configuration |
|---|---|
| Simplicity | ❌ |
| Multiple editors | ✅ |
| Operate on directories | ✅ |
| Source control | ✅ |
| Change review processes | ✅ |
| Audit trails | ✅ |
| Standardization | ✅ |
| Reproducibility | ✅ |
| Idempotence | ✅ |
| Automation | ✅ |
Table 3: Features of the declarative object configuration.
Zusammenfassung
Ziel dieses Artikels ist es, den Wert des deklarativen Ansatzes zur Verwaltung von Kubernetes aufzuzeigen. Tabelle 4 vergleicht die Funktionen der drei verschiedenen Kubernetes-Verwaltungstechniken. Weitere Informationen zu diesen Optionen finden Sie unter Managementtechniken.
| Management technique | Imperative commands | Imperative object configuration | Declarative object configuration |
|---|---|---|---|
| Simplicity | ✅ | 🔶 | ❌ |
| Multiple editors | ✅ | ❌ | ✅ |
| Operate on directories | ❌ | 🔶 | ✅ |
| Source control | ❌ | ✅ | ✅ |
| Change review processes | ❌ | ✅ | ✅ |
| Audit trails | ❌ | ✅ | ✅ |
| Standardization | ❌ | ✅ | ✅ |
| Reproducibility | ❌ | ✅ | ✅ |
| Idempotence | ❌ | ❌ | ✅ |
| Automation | ❌ | ❌ | ✅ |
Table 4: Comparison of the features of the management techniques.
Zunächst kann zwischen der Verwaltung über imperative Befehle und über Kubernetes-Objektkonfigurationsdateien unterschieden werden. Beim imperativen Ansatz mit imperativen Befehlen werden Handlungen definiert. In Kubernetes-Objektkonfigurationsdateien wird der Status definiert. In den Konfigurationsdateien wird der gewünschte Systemzustand deklarativ beschrieben.
Zweitens kann zwischen Management über imperative Objektkonfiguration und deklarativer Objektkonfiguration unterschieden werden. Beim imperativen Ansatz mit imperativer Objektkonfiguration wird der Zustand mit einem imperativen Befehl kommuniziert. Beim deklarativen Ansatz mit deklarativer Objektkonfiguration wird der Zustand mit einem deklarativen Befehl kommuniziert. Basierend auf dem tatsächlichen und dem gewünschten Systemzustand werden im deklarativen Ansatz notwendige Aktionen abgeleitet.
Die Verwaltungstechnik mit imperativen Befehlen eignet sich gut für erste Schritte mit Kubernetes in einer Entwicklungsumgebung. Dieser zwingende Ansatz ermöglicht jedoch keine DevOps-Praktiken. Letztendlich ist eine Automatisierung unmöglich.
Die Verwaltungstechnik mit imperativer Objektkonfiguration ist eine Hybridmethode, da sie den gewünschten Kubernetes-Zustand deklarativ beschreibt, den Zustand jedoch mit einem imperativen Befehl an Kubernetes kommuniziert. Dieser hybride Ansatz ermöglicht viele DevOps-Praktiken. Aber letztendlich macht der Mangel an Idempotenz eine Automatisierung unmöglich.
Die Verwaltungstechnik mit deklarativer Objektkonfiguration ist die Empfehlung für Produktionsumgebungen von Kubernetes. Dieser deklarative Ansatz ermöglicht DevOps-Praktiken. Und das ultimative Ziel der Automatisierung ist möglich.
Die deklarative Objektkonfiguration ist die ausgefeilteste Verwaltungstechnik und diejenige mit der steilsten Lernkurve. Um seine Komplexität zu reduzieren, ist es wichtig, diesen deklarativen Ansatz in eine breitere Palette von Praktiken einzubetten. Diese Artikelserie empfiehlt die GitOps-Prinzipien.
Das erste GitOps-Prinzip ist der deklarative Ansatz. Dieses Paradigma plädiert dafür, das gesamte System deklarativ zu beschreiben. Die deklarative Objektkonfiguration ist die Kubernetes-Verwaltungstechnik, die dieses erste GitOps-Prinzip ermöglicht.
Das könnte Sie auch interessieren:

")




Andy Wirtz is a Senior IT Consultant at ATIX AG, Germany. He supports his clients in the setup and configuration of container platforms, in the deployment of cloud native services, and in the development of microservice applications. He is an expert in the technical practices of DevOps, Continuous Delivery and automation. He provides in-depth trainings, workshops and webinars about Kubernetes and OpenShift.

