GitOps – Kubernetes The Easy Way
Part I: Best practices with Kubernetes management techniques
Managing Kubernetes should be simple, straightforward, and clear. Well-known DevOps practices and ultimately automation should be accessible through management technology. The first GitOps principle, the declarative approach, is the essential Kubernetes management technique to leverage the desired functionality.
Introduction
This is the first article in a series about GitOps and its paradigms to simplify Kubernetes configuration management. The four GitOps principles are: Declarative approach:
- The entire system is described declaratively,
- Version control: The canonically desired system state is versioned in Git,
- Deployment automation: Approved changes are automatically applied to the system.
- Continuous delivery: Software agents ensure accuracy and alerts in the event of deviations.
This article introduces various Kubernetes management techniques and highlights the importance and value of the declarative approach. The declarative approach is the first GitOps principle and recommends describing the entire system declaratively. The following sections discuss three Kubernetes management techniques. One technique is an approach without Kubernetes object configuration files:
- compelling commands.
The other two techniques are based on Kubernetes object configuration files:
- mandatory object configuration,
- declarative object configuration.
Imperative Commands
Create objects
The easiest way to interact with the Kubernetes API is through imperative commands. This management technique works without Kubernetes object configuration files but with mandatory steps. Imperative commands can be divided into verb-driven and object-driven commands. For example, a deployment object for the voting containers can be generated by a verb-driven, imperative command:
kubectl run vote --image=andywirtzk8s/voting-vote:v1.0 --port=8080 -l "app=vote" -r 3 -n voting
This command creates the Vote deployment object in the Kubernetes Voting namespace. Object creation requires only a single step and no configuration file is required. You can find the image at Dockerhub. A service object for the voting containers can be generated with:
kubectl expose deployment vote --name vote -n voting
This command creates the Vote service object in the Kubernetes Voting namespace. A HorizontalPodAutoscaler object for the voting containers can be generated with:
kubectl autoscale deployment vote --min 2 --max 5 --cpu-percent 80 --name vote -n voting
This command creates the Vote HorizontalPodAutoscaler object in the Kubernetes voting namespace. These three commands are verb controlled. The next command is object driven. The object-driven command can be used to create various Kubernetes objects. For example, a ConfigMap object for the voting containers can be generated with:
kubectl create configmap options --from-literal A=Imperative --from-literal B=Declarative -n voting
This command creates the Options ConfigMap object in the Kubernetes voting namespace. Figure 1 shows the four mandatory commands for creating Kubernetes objects.

Figure 1: Create objects with imperative commands.
Update objects
The management technique of compelling commands to interact with the Kubernetes API can also be used to modify Kubernetes objects. Three available imperative commands are verb-driven. For example, a deployment object can be scaled horizontally with:
kubectl scale deployment vote --replicas 2 -n voting
This command updates the replica field of the Vote deployment object in the Kubernetes Voting namespace. The change only requires a single step and no configuration file is required. A Kubernetes object can be annotated with the following
kubectl annotate deployment vote atix.de/technique='imperative commands' -n voting
This command updates the annotation field of the Vote deployment object in the Kubernetes Voting namespace. A Kubernetes object can be marked as follows:
kubectl label deployment vote technique=imperative -n voting
This command updates the Labels field of the Vote deployment object in the Kubernetes Voting namespace. Alternatively, an aspect controlled command can be used. An aspect-driven command can be used to change different fields for different Kubernetes objects. For example, a Kubernetes object’s field can be changed as follows:
kubectl set image deployment vote vote=andywirtzk8s/voting-vote:v1.1 -n voting
This command updates the image field of the Vote deployment object’s pod template in the Kubernetes Voting namespace and triggers a rolling update. Additionally, there are two mandatory commands with a more general approach to modifying live Kubernetes objects. For example, a specific field of a Kubernetes object can be modified by a patch string using:
kubectl patch deployment vote -p '{"spec": {"minReadySeconds": 10}}' -n voting
This command updates the minReadySeconds field of the vote deployment object in the Kubernetes vote namespace. An understanding of the JSON format of Kubernetes API resources is required here. For major changes to a Kubernetes object, the live object can be opened in the standard editor with:
kubectl edit deployment vote -n voting
Changes can be made and saved using the editor. For example:
...
- image: andywirtzk8s/voting-vote:v1.1
name: vote
envFrom:
- prefix: OPTION_
configMapRef:
name: options
livenessProbe:
httpGet:
path: /
port: http
readinessProbe:
httpGet:
path: /
port: http
ports:
- containerPort: 8080
name: http
...
This example adds the envFrom, livenessProbe, readinessProbe, and ports[0].name fields to the live deployment object. After you make these changes, save the file, and exit the editor, the Vote deployment object in the Kubernetes Voting namespace is updated and a rolling update is triggered. An understanding of the YAML format of Kubernetes API resources is required here. Figure 2 shows the six mandatory commands for updating Kubernetes objects.
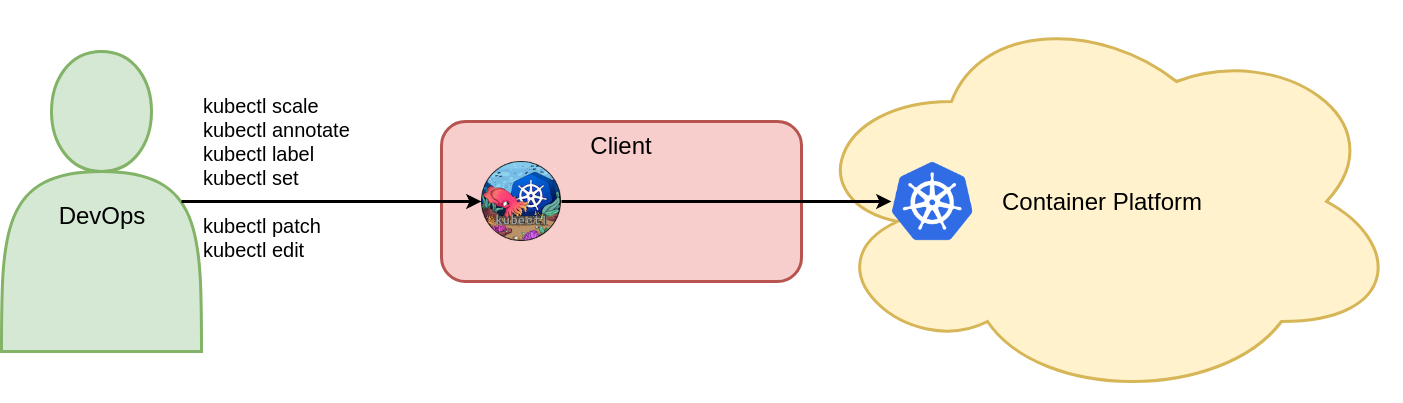
Figure 2: Update objects with imperative commands.
Delete objects
To delete a Kubernetes object, there is a mandatory object-driven command. For example, a Kubernetes object can be deleted as follows:
kubectl delete deployment vote -n voting
This command deletes the Vote deployment object in the Kubernetes Voting namespace. Figure 3 shows the one mandatory command for deleting Kubernetes objects.
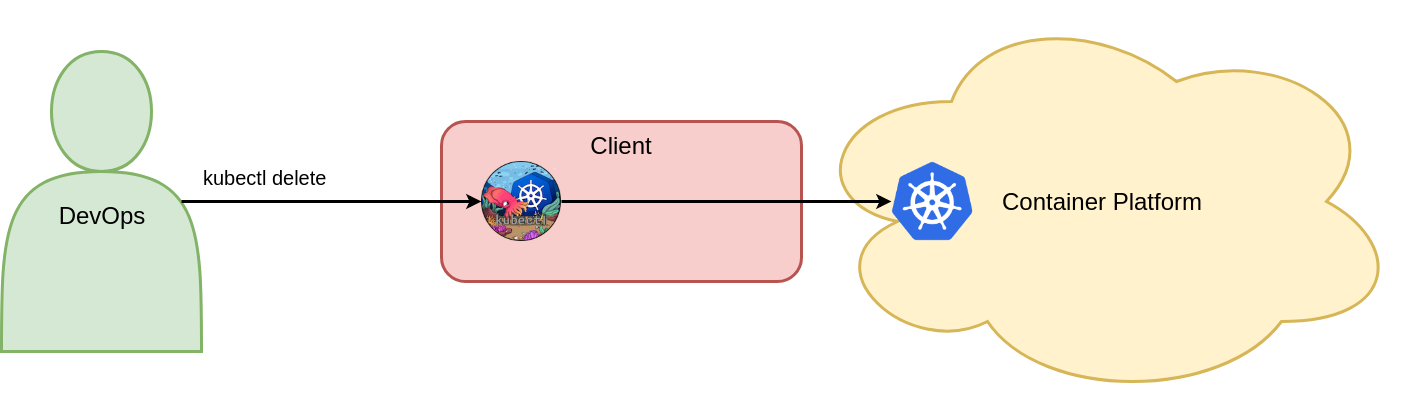
Figure 3: Delete objects with imperative commands.
Advantages and challenges
The big advantage of Kubernetes management with imperative commands is its simplicity. Imperative commands are simple, easy to learn and easy to remember. Configuration changes only require a single step. Additionally, changes to Kubernetes objects can be made by multiple authors without conflict. The biggest disadvantage of Kubernetes management with imperative commands is the lack of Kubernetes object configuration files. Without the Kubernetes object configuration files, automation, standardization, and reproducibility are not possible. DevOps practices such as source control, change review processes, and audit trails related to changes are inaccessible. Table 1 lists the features of the mandatory commands for managing Kubernetes objects. For more information about this management technique, see Imperative Commands.
| Management technique | Imperative commands |
|---|---|
| Simplicity | ✅ |
| Multiple editors | ✅ |
| Operate on directories | ❌ |
| Source control | ❌ |
| Change review processes | ❌ |
| Audit trails | ❌ |
| Standardization | ❌ |
| Reproducibility | ❌ |
| Idempotence | ❌ |
| Automation | ❌ |
Table 1: Features of the imperative commands.
Imperative object configuration
Create objects
A more sophisticated way of interacting with the Kubernetes API is through mandatory object configuration. This management technique works with Kubernetes object configuration files. For example, a deployment object for the voting containers can be defined in a file:
FILE=${HOME}/configs/voting/vote/deployment.yaml
The content of the file is a YAML descriptor of the deployment object:
apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
atix.de/technique: imperative object configuration
labels:
app: vote
technique: imperative
name: vote
namespace: voting
spec:
minReadySeconds: 10
replicas: 3
selector:
matchLabels:
app: vote
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
type: RollingUpdate
template:
metadata:
labels:
app: vote
spec:
containers:
- image: andywirtzk8s/voting-vote:v1.0
name: vote
envFrom:
- prefix: OPTION_
configMapRef:
name: options
livenessProbe:
httpGet:
path: /
port: http
readinessProbe:
httpGet:
path: /
port: http
ports:
- containerPort: 8080
name: http
This is a YAML manifest that represents the desired state of the deployment object. This deployment object can be generated with:
kubectl create -f ${FILE}
This command creates the Vote deployment object in the Kubernetes Voting namespace. For the command to work, it is required that the Vote deployment object does not previously exist in the Voting namespace. Figure 4 shows the one mandatory object configuration command for creating Kubernetes objects.
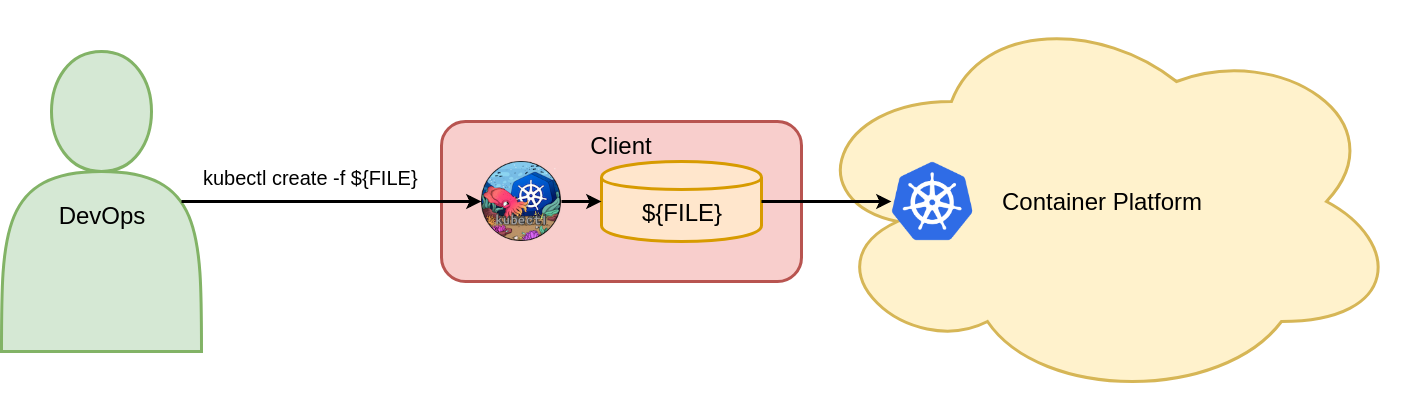
Figure 4: Create objects with imperative object configuration.
Update objects
The management technique of forcing object configuration to interact with the Kubernetes API can also be used to modify Kubernetes objects. For example, the deployment object configuration can be replaced with:
kubectl replace -f ${FILE}
Abhängig von der im YAML-Manifest des Vote-Bereitstellungsobjekts vorgenommenen Änderung stellt Kubernetes den neuen gewünschten Zustand sicher. Wenn sich das Replikatfeld ändert, wird das Live-Bereitstellungsobjekt horizontal skaliert. Wenn sich das Bildfeld in der Pod-Vorlage des Bereitstellungsobjekts ändert, wird ein fortlaufendes Update ausgelöst. Kubernetes ersetzt das Live-Objekt, auch wenn keine Konfigurationsänderung erfolgt. Dies führt zu einem obligatorischen, nicht idempotenten Konfigurationsmanagement. Damit der Befehl funktioniert, muss das Vote-Bereitstellungsobjekt zunächst im Voting-Namespace vorhanden sein. Abbildung 5 zeigt den einen obligatorischen Objektkonfigurationsbefehl zum Aktualisieren von Kubernetes-Objekten.
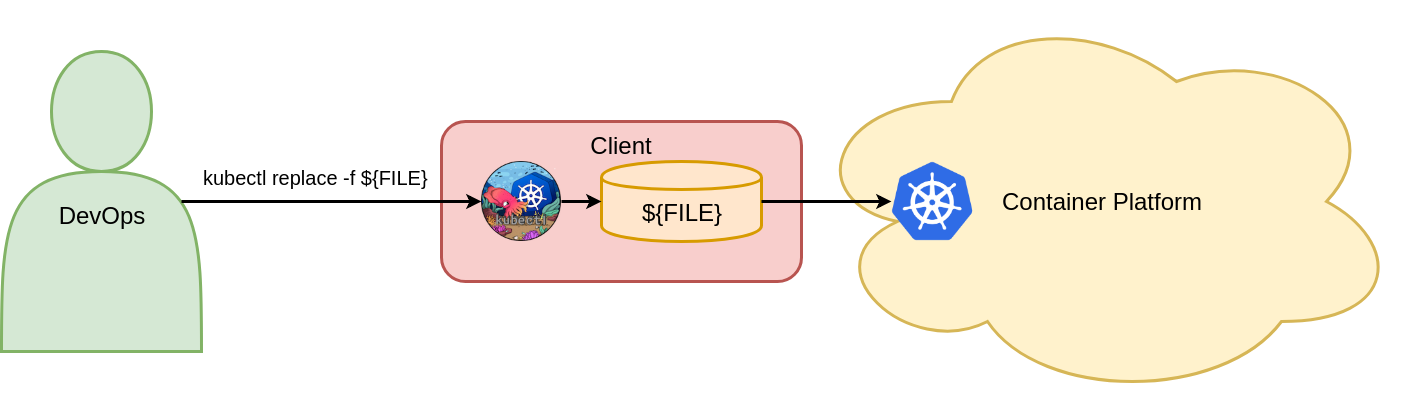
Figure 5: Update objects with imperative object configuration.
Delete objects
To delete a Kubernetes object, there is a command within imperative object configuration technique. For example, a Kubernetes object can be deleted as follows:
kubectl delete -f ${FILE}
This command deletes the Vote deployment object in the Kubernetes Voting namespace. Figure 6 shows the one mandatory object configuration command for deleting Kubernetes objects.
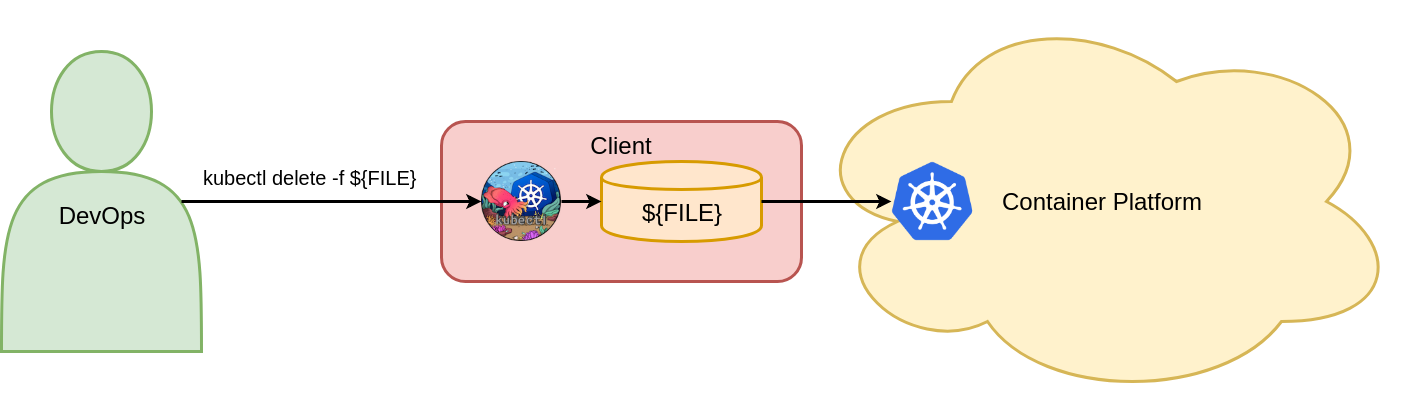
Figure 6: Delete objects with imperative object configuration.
Advantages and challenges
The big advantage of Kubernetes management with mandatory object configuration is the recording of the desired state in the form of Kubernetes object configuration files. These Kubernetes object configuration files can enable standardization and reproducibility.
DevOps practices such as the use of a source control system, change review processes, and audit trails associated with changes can be accessed. The biggest disadvantage of Kubernetes management with imperative object configuration is the lack of idempotent configuration management feature. Updates occur by replacing the live object, even if there is no configuration mismatch between the configuration file and the live object.
When multiple editors manage the same Kubernetes object, changes from one source may be lost by the second source’s replace command. Such updates to live objects must be reflected in the configuration files. Additionally, there are additional requirements for the create and replace commands to work. Mandatory object configuration works best for files, not directories. All of these issues make it difficult to make or automate configuration changes. Table 2 lists the features of mandatory object configuration for managing Kubernetes objects. For more information about this management technique, see Imperative Object Configuration.
| Management technique | Imperative object configuration |
|---|---|
| Simplicity | |
| Multiple editors | ❌ |
| Operate on directories | |
| Source control | ✅ |
| Change review processes | ✅ |
| Audit trails | ✅ |
| Standardization | ✅ |
| Reproducibility | ✅ |
| Idempotence | ❌ |
| Automation | ❌ |
Table 2: Features of the imperative object configuration.
Declarative object configuration
Create objects
The most sophisticated way to interact with the Kubernetes API is through declarative object configuration. This management technique works with Kubernetes object configuration files. It supports operating directories containing Kubernetes object configuration files. For example, a directory can be defined that contains YAML descriptor files of Kubernetes objects:
DIR=${HOME}/configs/voting/vote
This directory stores the YAML manifests that represent the desired state of the deployment, ingress, and service object for the voting containers:
.
├── deployment.yaml
├── ingress.yaml
└── service.yaml
The files can be found on Github. The three Kubernetes objects can be printed using:
kubectl diff -f ${DIR}/
This command prints the Kubernetes Vote Deployment, Vote Ingress, and Vote Service objects and allows them to be inspected. The output not only shows the fields defined in the YAML manifests, but is also enriched with the standard Kubernetes field values. The three Kubernetes objects can be generated with:
kubectl apply -f ${DIR}/
This command posts the vote deployment, vote ingress, and vote service objects to Kubernetes and creates them in the voting namespace. There are no requirements as to whether the objects exist beforehand or not. Figure 7 shows the two relevant declarative object configuration commands for creating Kubernetes objects.
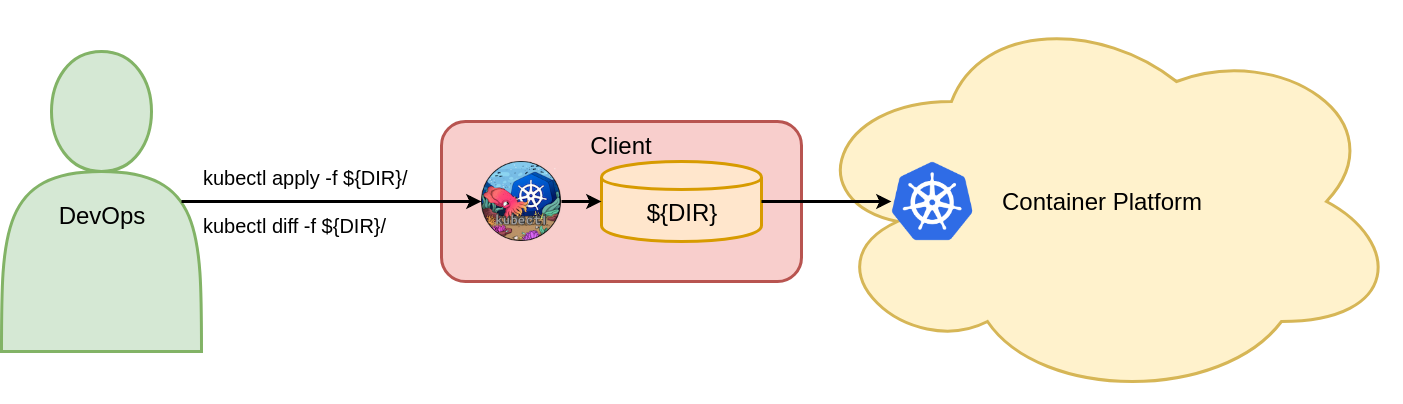
Figure 7: Create objects with declarative object configuration.
Update objects
The declarative object configuration management technique for interacting with the Kubernetes API can also be used to modify Kubernetes objects. The difference between the locally stored YAML manifests and the live Kubernetes object counterparts can be expressed as follows:
kubectl diff -f ${DIR}/
With this command, the configuration drift of the vote deployment, vote ingress, and vote service objects of Kubernetes is printed and can be checked. The output only shows the fields that are not synchronized between the locally stored Kubernetes object configuration files and the live Kubernetes objects. Regardless of whether you see a difference or not, the three Kubernetes objects can be updated with:
kubectl apply -f ${DIR}/
There are three different scenarios to consider with this command. In the first case, the Kubernetes object did not exist before. Here it is created by Kubernetes as described in the last subsection. In the second case, there is no difference between the YAML manifest and the live Kubernetes objects. No action is taken here. In the third case, one or more fields in one or more Kubernetes objects were changed.
Here a merge patch is calculated and the Kubernetes objects are patched by Kubernetes. With this merge patch calculation, the desired system state is not only described declaratively in the YAML manifests, but also communicated declaratively to Kubernetes. This leads to idempotent configuration management. For example, if the replica field and image field are changed in the locally stored Kubernetes object configuration files, the live deployment object scales horizontally and triggers a rolling refresh, while the live ingress and service objects remain untouched. On the other hand, if a field is not defined in the YAML manifest file, the command will ignore it.
If some mandatory changes were made to default field values that are not defined in a Kubernetes object configuration file, that change will not be overwritten. Figure 8 shows the two relevant declarative object configuration commands for updating Kubernetes objects.
Figure 8: Update objects with declarative object configuration.
Delete objects
To delete Kubernetes objects, there is a command within the declarative object configuration technique. For example, the three Kubernetes objects can be deleted with:
kubectl delete -f ${DIR}/
This command deletes the Vote Deployment, Vote Ingress, and Vote Service objects in the Kubernetes Voting namespace. Figure 9 shows the one declarative object configuration command for deleting Kubernetes objects.
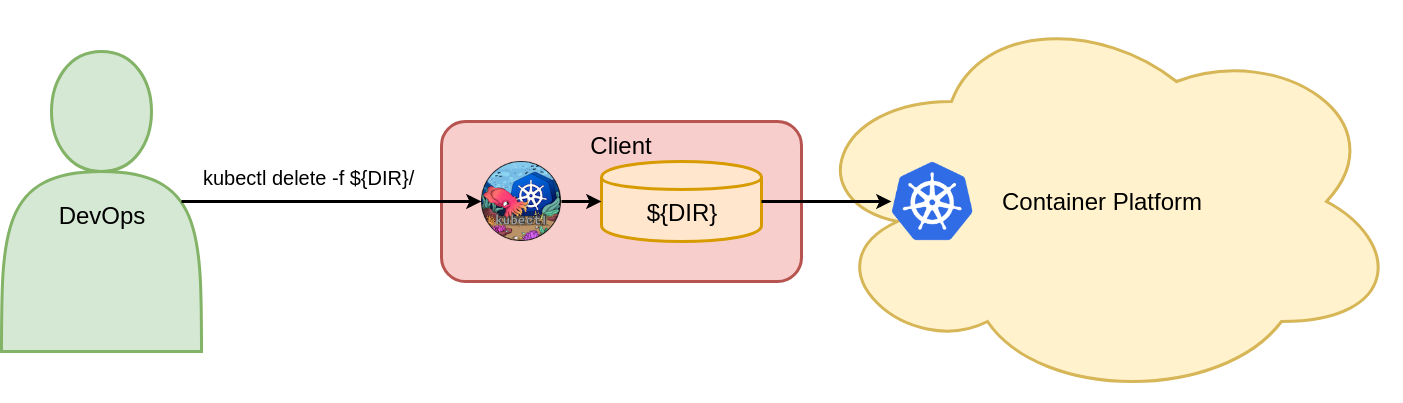
Figure 9: Delete objects with declarative object configuration.
Advantages and challenges
The main advantage of Kubernetes management with declarative object configuration is support for operating in directories containing Kubernetes object configuration files and automatic detection of the operation type per object. Kubernetes can automatically decide whether an object or field should be created, patched, deleted, or left untouched. This enables idempotent configuration management.
The directories that contain the Kubernetes object configuration files can enable automation, standardization, and reproducibility. DevOps practices such as the use of a source control system, change review processes, and audit trails associated with changes can be accessed.
Kubernetes management with declarative object configuration is the most powerful management technique. This comes at the cost of a steeper learning curve, as the patch merge calculation can lead to unexpected behavior. Table 3 lists the features of declarative object configuration for managing Kubernetes objects. For more information about this management technique, see declarative object configuration.
| Management technique | Declarative object configuration |
|---|---|
| Simplicity | ❌ |
| Multiple editors | ✅ |
| Operate on directories | ✅ |
| Source control | ✅ |
| Change review processes | ✅ |
| Audit trails | ✅ |
| Standardization | ✅ |
| Reproducibility | ✅ |
| Idempotence | ✅ |
| Automation | ✅ |
Table 3: Features of the declarative object configuration.
Conclusion
The goal of this article is to demonstrate the value of the declarative approach to managing Kubernetes. Table 4 compares the features of the three different Kubernetes management techniques. For more information about these options, see Management Techniques.
| Management technique | Imperative commands | Imperative object configuration | Declarative object configuration |
|---|---|---|---|
| Simplicity | ✅ | ❌ | |
| Multiple editors | ✅ | ❌ | ✅ |
| Operate on directories | ❌ | ✅ | |
| Source control | ❌ | ✅ | ✅ |
| Change review processes | ❌ | ✅ | ✅ |
| Audit trails | ❌ | ✅ | ✅ |
| Standardization | ❌ | ✅ | ✅ |
| Reproducibility | ❌ | ✅ | ✅ |
| Idempotence | ❌ | ❌ | ✅ |
| Automation | ❌ | ❌ | ✅ |
Table 4: Comparison of the features of the management techniques.
First, a distinction can be made between management via imperative commands and via Kubernetes object configuration files. In the imperative approach with imperative commands, actions are defined. Kubernetes object configuration files define state. The desired system state is described declaratively in the configuration files.
Secondly, a distinction can be made between management via imperative object configuration and declarative object configuration. In the imperative approach with imperative object configuration, the state is communicated with an imperative command. In the declarative approach with declarative object configuration, the state is communicated with a declarative command. Based on the actual and desired system status, necessary actions are derived in the declarative approach.
The imperative command management technique is well suited for getting started with Kubernetes in a development environment. However, this imperative approach does not enable DevOps practices. Ultimately, automation is impossible.
The imperative object configuration management technique is a hybrid method because it describes the desired Kubernetes state declaratively, but communicates the state to Kubernetes with an imperative command. This hybrid approach enables many DevOps practices. But ultimately the lack of idempotence makes automation impossible.
The declarative object configuration management technique is the recommendation for Kubernetes production environments. This declarative approach enables DevOps practices. And the ultimate goal of automation is possible.
Declarative object configuration is the most sophisticated management technique and the one with the steepest learning curve. To reduce its complexity, it is important to embed this declarative approach into a broader range of practices. This series of articles recommends the GitOps principles.
Declarative object configuration is the most sophisticated management technique and the one with the steepest learning curve. To reduce its complexity, it is important to embed this declarative approach into a broader range of practices. This series of articles recommends the GitOps principles.
You might also like
")

")



Andy Wirtz is a Senior IT Consultant at ATIX AG, Germany. He supports his clients in the setup and configuration of container platforms, in the deployment of cloud native services, and in the development of microservice applications. He is an expert in the technical practices of DevOps, Continuous Delivery and automation. He provides in-depth trainings, workshops and webinars about Kubernetes and OpenShift.

